

In our introduction post we started our journey into how everything began. In our second post we will take a look at testing out more advanced concepts and the problems that occured on our way.
In the last post of this series we’ve gone the way to our first prototype and we build it. This time we will take the next steps into a new way of thinking about IT infrastructure.
We build our prototype to make providing virtual machines simpler but not only for us as the guys managing all the infrastructure also for the people using it.
When automation changes your work
By starting to introduce an early version of something that could be called an API, we achieved an other success. The API gave us a way to integrate the virtual machine provisioning deeper into different processes. For example, development and test pipelines that could provision the systems when they were needed and throw them away after the work is done. This gives us a way better resource usage since it reduces virtual machines just idling around waiting for being used.
One of our R&D teams integrated this Self-Service prototype into their testing pipelines allowing them to create the needed system on demand while throwing away unneeded ones. Since they always got a fresh system that is up-to-date they don’t have to care about snapshots and updates on the system itself or strange system configurations.
This made their testing pipeline more stable and consistent while completely elliminating the need for communication to get a virtual machine from our IT department.
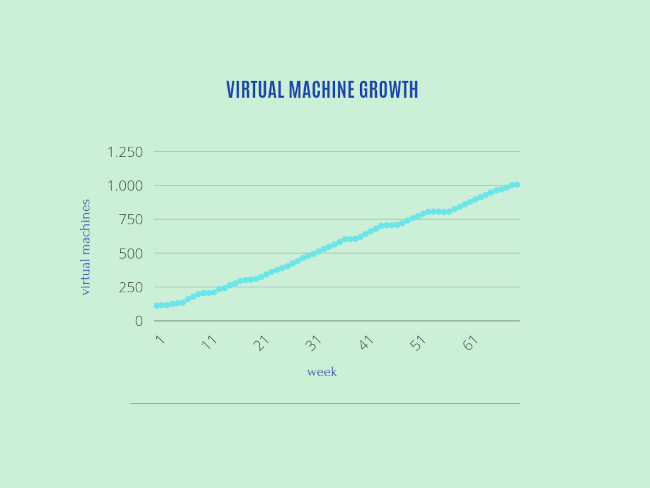
About 2 years later, we scaled the number of virtual machines from about 100 up to a around 1000 virtual machines. This increase would not have been possible if we had continued to do everything by hand. The creation of these virtual machines was completely automated and maintained by this early prototype.
Templates
In the past we used templates to simplify the virtual machine creation. But since we had so many different use cases and requirements we run into our own template hell. Having up to 40 templates that all have to be kept up-to-date somehow and maintained when infrastructure changes occure, we decided that the maintenance of templates is not worth the effort.
But now since we have a system that is able to automate the creation, installation and configuration we could use it to automate the whole maintenance process for templates as well.
We build another set of automation to maintaine all of our templates and integrated the templates into the building process.
This was a facinating idea since it reduces the build time even more and we were able to build systems in under a minute making our provisioning process nearly real time deployment for virtual machines. But we learned this this comes with a price. Templates are way harder to customize. You can create a new template for every customization resulting in a lot of templates that need some space for laying around and creates more load on the maintainance system that runs every night to rebuild all the templates. Or you have to do the customization afterwards.
Doing the customization afterwards we run into a lot of issues since we were able to provide virtual machines for every environment but not for every environment we had possibilitys to execute code on the systems to customize. This could be solved using orchestration tools, but the more easy solution which we took later when building Virtomize itself is to do the customization within the installation. But when you do the customization within the installation you cant use templates anymore since they are already installed.
Templates are a bit of double-edged sword. Either you have a lot of them or you can’t use them at all.
Maintainance Hell
Our work shifted from doing the work itself to maintaining the system doing it for us. As it is often the case, prototypes are … prototypes and maintenance became a mess. Many third party tools and data backends were involved. A lot of automation code layers where involved. Integrated processes forced the system to work properly to not create dependency problems. Updating parts of the toolchain regularly broke everything since many software developers don’t follow semantic versioning so you never know if things break. Stability was a big problem at this point. We faced a lot of issues creating downtime to the whole system causing delays and a lot of other issues.
Handling errors having so many different tools involved was a real problem. When things go wrong this often results in broken virtual machines laying around.
If you want to know how we managed to leave the maintainance hell checkout the next post of our fascinating story series
Thanks for reading so far and see you in the Virtomize.